B-Tree
in Development on Database
B-Tree
B-Tree란?
인덱스는 B-Tree 자료구조를 이용하여 테이블의 요소를 빠르게 탐색하도록 설계되어 있다. MySQL에서는 인덱스를 구현할 때 페이지로 구성된 B-Tree 구조를 사용한다. B-Tree 구조는 데이터를 검색할 때(SELECT 문을 사용할 때) 매우 뛰어난 성능을 발휘한다.
B-Tree의 장점
일반적인 Tree 구조를 먼저 살펴보자.
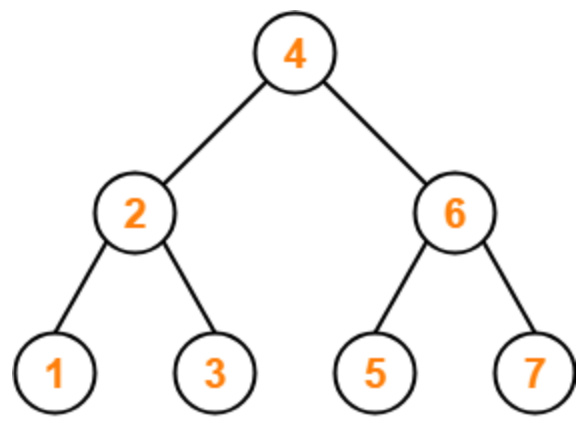
일반적인 Tree는 평균적으로 탐색에 대한 시간 복잡도로 O(logN)을 가진다. 그러나 이는 지극히 ‘평균적인’ 시간 복잡도이다.
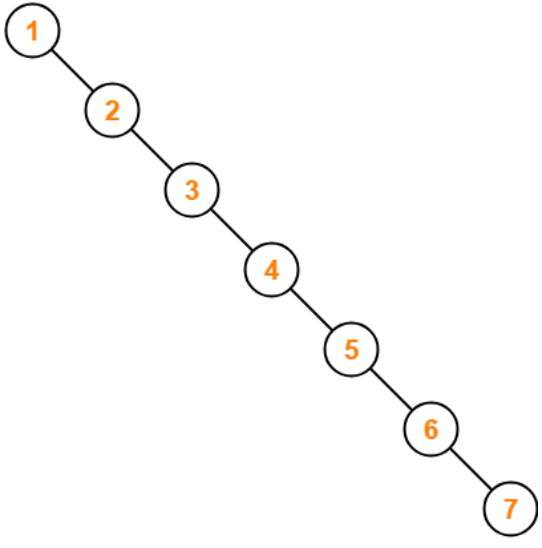
만약 트리 노드의 요소가 위처럼 한쪽 방향으로만 쏠려있다면, 최악의 탐색 시간은 O(N)을 가지게 된다. 이러한 경우를 방지하기 위해 우리는 밸런스 트리(Balanced Tree)를 이용할 수 있다.
밸런스 트리(Balanced Tree)란?
트리의 노드가 한 방향으로 쏠리지 않도록, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재정렬되어 왼쪽과 오른쪽 자식 양쪽 수의 밸런스를 유지하는 트리이다. 항상 양쪽 자식의 밸런스를 유지하므로, 무조건 O(logN)의 시간 복잡도를 가지게 된다.
다만 재정렬되는 작업으로 인해 노드 삽입 및 삭제 시 일반적인 트리보다 성능이 떨어지게 된다. 그러므로 밸런스 트리는 삽입/삭제의 성능을 희생하고 탐색에 대한 성능을 높였다고 볼 수 있다.
밸런스 트리는 대표적으로 RedBlack-Tree, B-Tree가 있다.
위에 설명한 것처럼 밸런스 트리는 최악의 경우에도 O(logN)이므로, 탐색 시간에 매우 효율적인 자료조이다. 그래서 데이터베이스의 인덱스는 밸런스 트리, 그 중 B-Tree를 선택했다.
인덱스의 자료구조로 O(1)인 해시 테이블을 쓰지 않고, O(logN)인 B-Tree를 사용한 이유
모든 자료구조와 그 어떤 알고리즘을 비교해도 탐색 시간이 가장 빠른 것은 바로 해시 테이블이다. 해시 테이블은 해시 함수를 통해 나온 해시 값을 이용하여 저장된 메모리 공간에 한 번에 접근을 하기 때문에 O(1)이라는 시간 복잡도를 가진다. (물론 해시 충돌 등으로 최악의 경우에 O(N)이 될 수 있지만, 평균적으로는 O(1)으로 볼 수 있다)
그러나 이는 온전히 ‘단 하나의 데이터를 탐색하는 시간’ 에만 O(1)이다. 예를 들어 1, 2, 3, 4, 5가 저장되어 있는 해시 테이블에서 3이라는 데이터를 찾을 때에만 O(1)이라는 것이다. (3이라는 데이터를 인풋으로 해시 함수를 통해 나온 해시 값으로 3이 저장된 메모리 공간에 접근을 할 것이기 때문이다)
‘그게 무엇이 문제이냐’라고 생각한다면 잠깐 이 부분을 놓쳤을 것이다.
우리는 DB에서 등호(=) 뿐 아니라 부등호(<, >)도 사용할 수 있다는 것을. 모든 값이 정렬되어있지 않으므로, 해시 테이블에서는 특정 기준보다 크거나 작은 값을 찾을 수 없다. 굳이 찾으려면 찾을 수는 있지만 O(1)의 시간 복잡도를 보장할 수 없고 매우 비효율적이다. 그렇기에 기준 값보다 크거나 작은 요소들을 항상 탐색할 수 있어야 하는 DB 인덱스 용도로 해시 테이블은 어울리지 않는 자료구조인 것이다.
정리하자면, 인덱스의 자료구조로 O(1)인 해시 테이블을 쓰지 않은 이유는 ‘범위 검색’에 비효율적이기 때문이다.
인덱스의 자료구조로 배열을 쓰지 않고, B-Tree를 사용한 이유

모든 데이터가 메모리 상 차례대로 저장되어 있어 접근이 매우 빠르다.(인덱스의 자료구조를 배열에 저장한다면 데이터의 순서를 정렬해서 넣을 것이다.) 탐색 속도로만 본다면 B-Tree보다 훨씬 빠르다. 뿐만 아니라, 해시 테이블과는 다르게 데이터들의 정렬 상태로 유지할 수 있으므로 부등호(<, >) 연산을 사용한 ‘범위 검색’에도 효율적이다.
하지만 배열이 B-Tree보다 빠른 것은 ‘탐색’뿐이다.
배열 내에서 데이터 저장, 삭제가 일어나는 순간 B-Tree보다 훨씬 비효율적인 성능이 발생하게 된다.
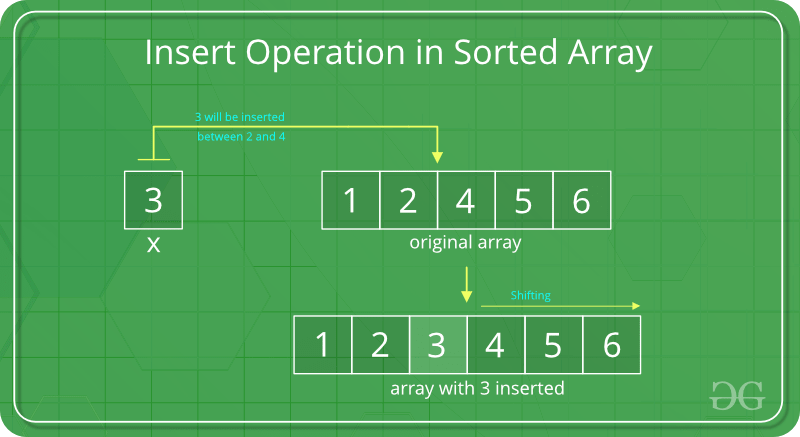
위 사진처럼 중간에 3이라는 데이터를 삽입하게 되면, 삽입될 해당 자리를 찾은 뒤 3보다 큰 데이터들은 한 칸씩 뒤로 물러나게 된다. 이때 뒤로 한 칸씩 이동하는 과정에서 평균 시간 복잡도가 O(N)이 걸리게 된다. 마치 데이터들이 다 같이 “자~ 하나, 둘, 셋!” 하며 동시에 이동하지 않는 한, 실제로는 CPU 연산에 의해 맨 뒤에 데이터부터 시작해서 각 한 칸씩 뒤로 이동하는 작업을 모두 거치게 될 것이다.
그나마 새롭게 삽입되는 데이터가 가장 큰 데이터라서 바로 맨 뒤에 저장된다면 O(logN)이 걸리겠지만(탐색 시간이 있기 때문), 최악의 경우인 가장 작은 데이터라면, 자리 탐색 시간인 O(logN)과 맨 앞에 새로운 데이터 삽입을 위해 모든 데이터를 한 칸씩 뒤로 이동하는 시간 O(N)으로, 총 O(N*logN)의 시간이 걸리게 된다.
이는 새로운 데이터 저장뿐 아니라, 삭제 시에도 동일하다. 삭제의 경우에는, 특정 데이터를 삭제하면 중간에 삭제된 데이터의 공간을 메꾸기 위해 뒤에서 한 칸씩 앞으로 이동하는 과정인 O(N)이 걸리게 되는 문제가 있기 때문이다.
데이터 수정이 일어날때도 퀵 정렬, 병합 정렬 등 배열 자료구조에서 O(N*logN) 시간으로 재정렬을 이루어야 한다는 점도 있다.
참고로 B-tree의 삽입, 삭제는 트리의 높이(h)에 따른 O(h)의 시간 복잡도를 가지는데, 이는 logN보다 훨씬 작은 값이다.
