클러스터 인덱스, 비클러스터 인덱스
in Development on Database
클러스터 인덱스, 비클러스터 인덱스
사전 용어 정리
노드 : 트리 구조에서 데이터가 존재하는 공간
→ MySQL에서는 이 노드를 페이지라고 한다. 페이지는 최소한의 저장 단위로 크기가 16KB이며, 아무리 작은 데이터를 저장하더라도 1개의 페이지(16KB)를 사용한다.
- 루트 노드 : 최상위 노드
- 리프 노드 : 최하위 노드
- 중간 노드 : 루트 노드와 리프 노드 사이에 있는 노드
인덱스 여부에 따른 데이터 삽입 방식
Case 1. 인덱스가 없는 구조에서의 데이터 삽입 방법
인덱스가 없는 테이블에 다음과 같은 데이터를 삽입했다고 가정하자.
CREATE TABLE TestTbl
(
UserInitial char(5) NOT NULL,
Age smallint NOT NULL
);
INSERT INTO TestTbl VALUES('TTT',25);
INSERT INTO TestTbl VALUES('SSS',75);
INSERT INTO TestTbl VALUES('AAA',15);
INSERT INTO TestTbl VALUES('RRR',34);
INSERT INTO TestTbl VALUES('QQQ',45);
INSERT INTO TestTbl VALUES('CCC',28);
INSERT INTO TestTbl VALUES('FFF',41);
INSERT INTO TestTbl VALUES('GGG',12);
INSERT INTO TestTbl VALUES('KKK',22);
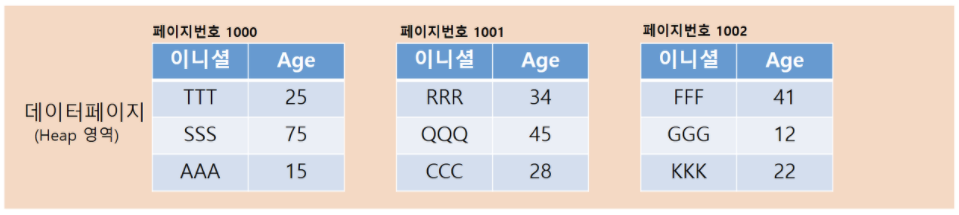
인덱스가 없는 구조에서는 위와 같이 데이터 페이지에 데이터들이 입력된 순서대로 기록이 된다. (구조를 쉽게 이해하기 위해 페이지당 데이터가 3개씩 들어간다고 가정하자.)
Case 2. 클러스터 인덱스 구조에서의 데이터 삽입 방법
클러스터 인덱스 구조에서 인덱스 페이지의 ‘루느 토드’, ‘중간 노드’들은 인덱스 행을 포함하게 구성되어 있다. ‘리프 노드’들은 기본 테이블의 데이터 페이지로 구성되어 있다. 기본 테이블 데이터 페이지의 데이터 값들은 인덱스 값을 기준으로 정려되어 있다. 인덱스 페이지를 통해 인덱스를 검색하여 해당하는 데이터 페이지를 찾아가도록 구성되어 있다.
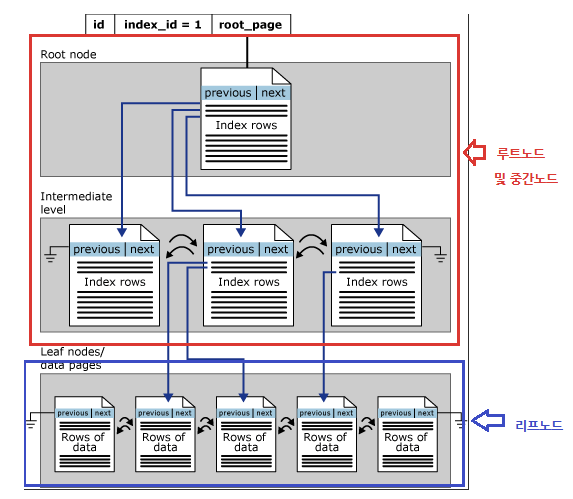
클러스터 인덱스를 사용시 작동 방식
1. 클러스터 인덱스 생성 시
특정 테이블에 UserInitial(이니셜)이라는 컬럼에 클러스터 인덱스를 구성하게 되면 내부구조는 다음과 같이 변한다.
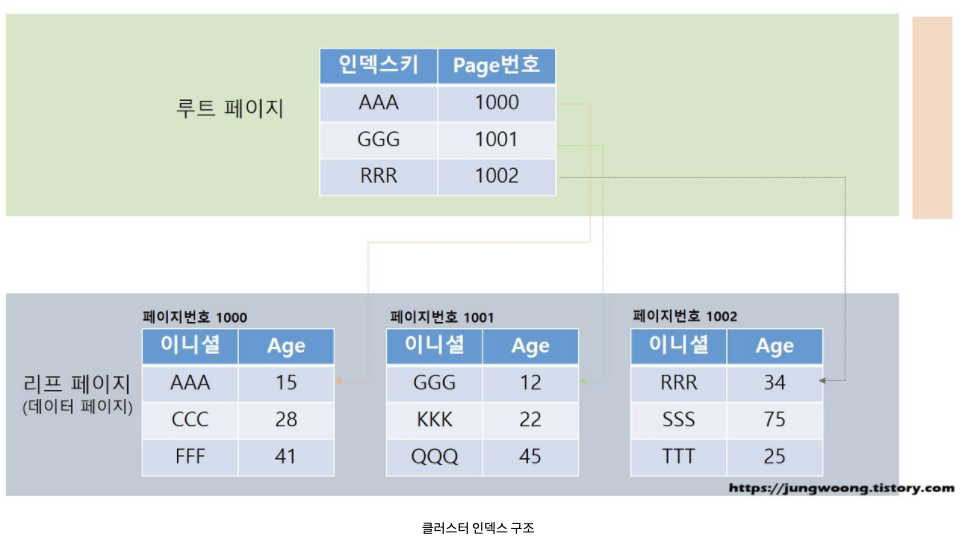
위와 같이 인덱스 페이지가 생성된다. 클러스터 인덱스 페이지의 루트 페이지에는 B-Tree로 정렬된 리프 페이지의 첫번째 UserInitial(이니셜) 컬럼의 값과 리프 페이지 번호로 맵핑이 된다. 클러스터 인덱스 페이지의 리프 페이지에는 데이터 페이지로 구성되어 있다. 데이터 페이지의 데이터들은 UserInitial(이니셜) 컬럼을 기준으로 정렬된다.
2. 클러스터 인덱스 검색 시
TestTbl 테이블에서 FFF 값을 검색한다면 아래와 같이 수행된다.
SELECT * FROM TestTbl WHERE UserInitial = 'FFF'
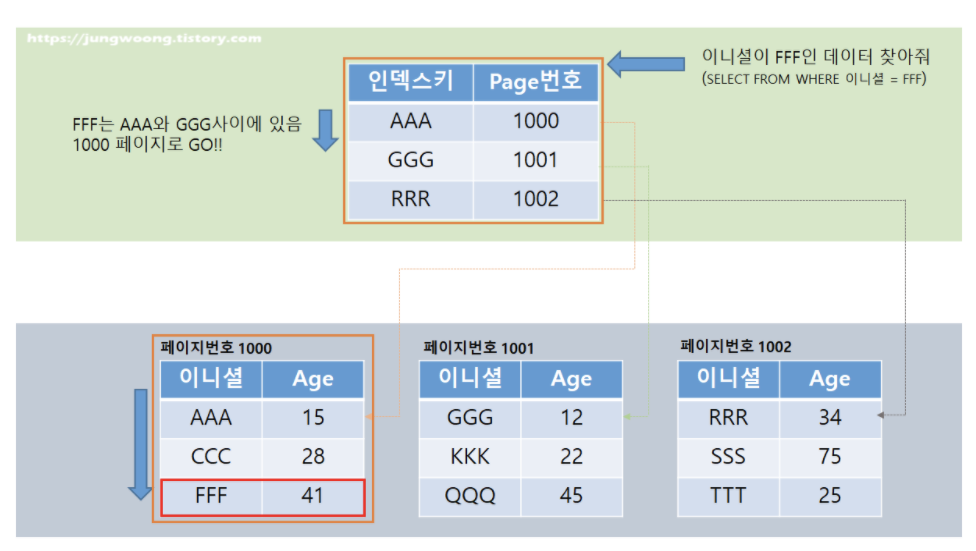
먼저 인덱스의 루트페이지를 접근해서 찾는 값이 어떤 리프 페이지(데이터 페이지)에 있는지 확인한다. 그런 다음 리프 페이지로 이동 후에, 페이지의 내부 행들을 검색해서 해당 데이터를 찾는 순서로 구성된다.
B-Tree를 활용한 검색에서는 총 2개의 페이지(루트 페이지 + 리프 페이지)만을 참조한 뒤에 바로 원하는 결과를 찾아낸다. 한 마디로, 인덱스 없이 일일이 검색하는 것에 비해서 훨씬 효율적이고 빠르다는 것이다.
3. 클러스터 인덱스 범위 검색 시
TestTbl 테이블에서 FFF에서 QQQ사이의 범위 검색한다면 DB내부에서는 아래와 같이 동작 할 것입니다.
SELECT * FROM TestTbl WHERE UserInitial >= 'FFF' AND UserInitial <= 'QQQ'
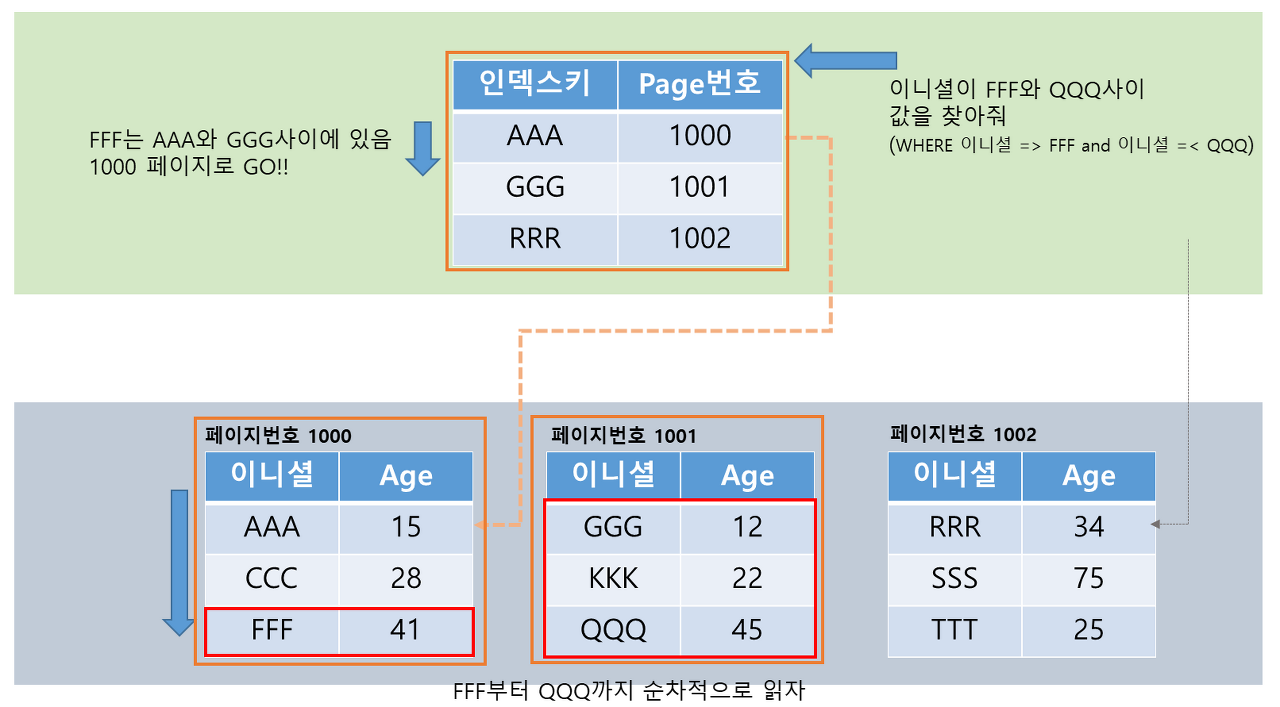
FFF의 페이지를 찾은 다음에 데이터가 정렬되어 있기 때문에, 순차적으로 QQQ가 나올 때까지 읽으면 검색 데이터를 효율적으로 모두 찾을 수 있게 된다. (비클러스터 인덱스의 경우 정렬되어 있지 않기 때문에 비효율적으로 검색하게 된다. 자세한 설명은 밑에서 다시 하겠다.)
4. 클러스터 인덱스 삽입 시
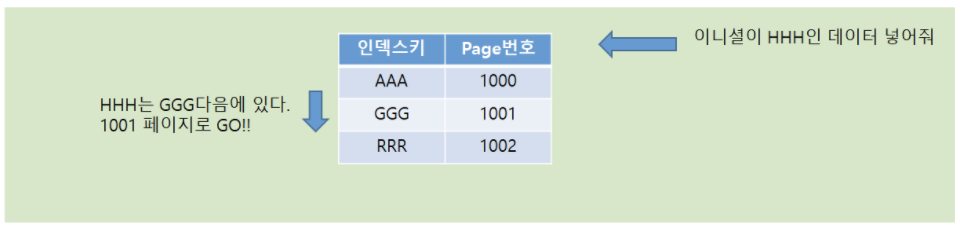
위의 구조에서 HHH라는 데이터를 INSERT하게 되면 밑과 같이 동작하게 된다.
1)
데이터를 삽입하려는데 페이지에 데이터가 이미 가득차있는 것을 확인한다. (만약 해당 페이지에 공간이 있었다면 인덱스 순서에 마도록 데이터를 넣고 작업이 끝났을 것이다.)
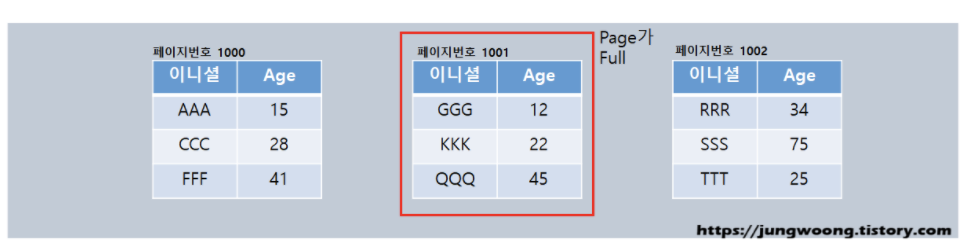
2)
페이지를 분할해서 비어 있는 페이지를 확보한 후, 각 리프 페이지에 페이지의 데이터를 공평하게 나눈다.
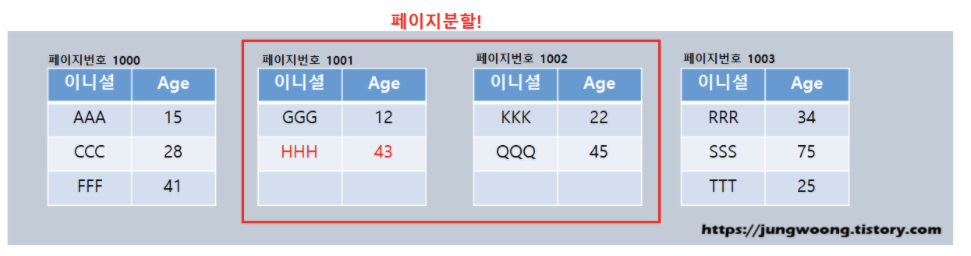
위 그림을 보면 데이터를 1개만 추가했는데 많은 작업이 일어났다. 페이지를 확보한 후 페이지 분할 작업을 하고, 루트 페이지에도 새로 등록된 페이지의 맨 위에 있는 데이터를 등록해야 한다. 만약에 데이터를 여러 개 추가해야 한다면 훨씬 더 과정이 복잡해질 것이다. 이 때문에 인덱스를 구성하면 데이터 변경(INSERT, UPDATE, DELETE)시 성능이 느려지는 것이다.
비클러스터 인덱스를 사용 시 작동 방식
1. 비클러스터 인덱스 생성 시
TestTbl 테이블의 “UserInitial” 컬럼에 비클러스터 인덱스를 구성하게 되면 내부구조는 다음과 같이 변한다.
인덱스 페이지의 루트 페이지에는 클러스터와 동일하게 인덱스 키와 리프페이지의 페이지 번호로 구성된다. 하지만 클러스터 인덱스와는 다르게, 인덱스 페이지의 리프 페이지는 데이터 페이지가 아닌 데이터 페이지의 포인터로 구성되어 있다. (실제로는 페이지 번호 + 행번호(RID)로 구성됨)
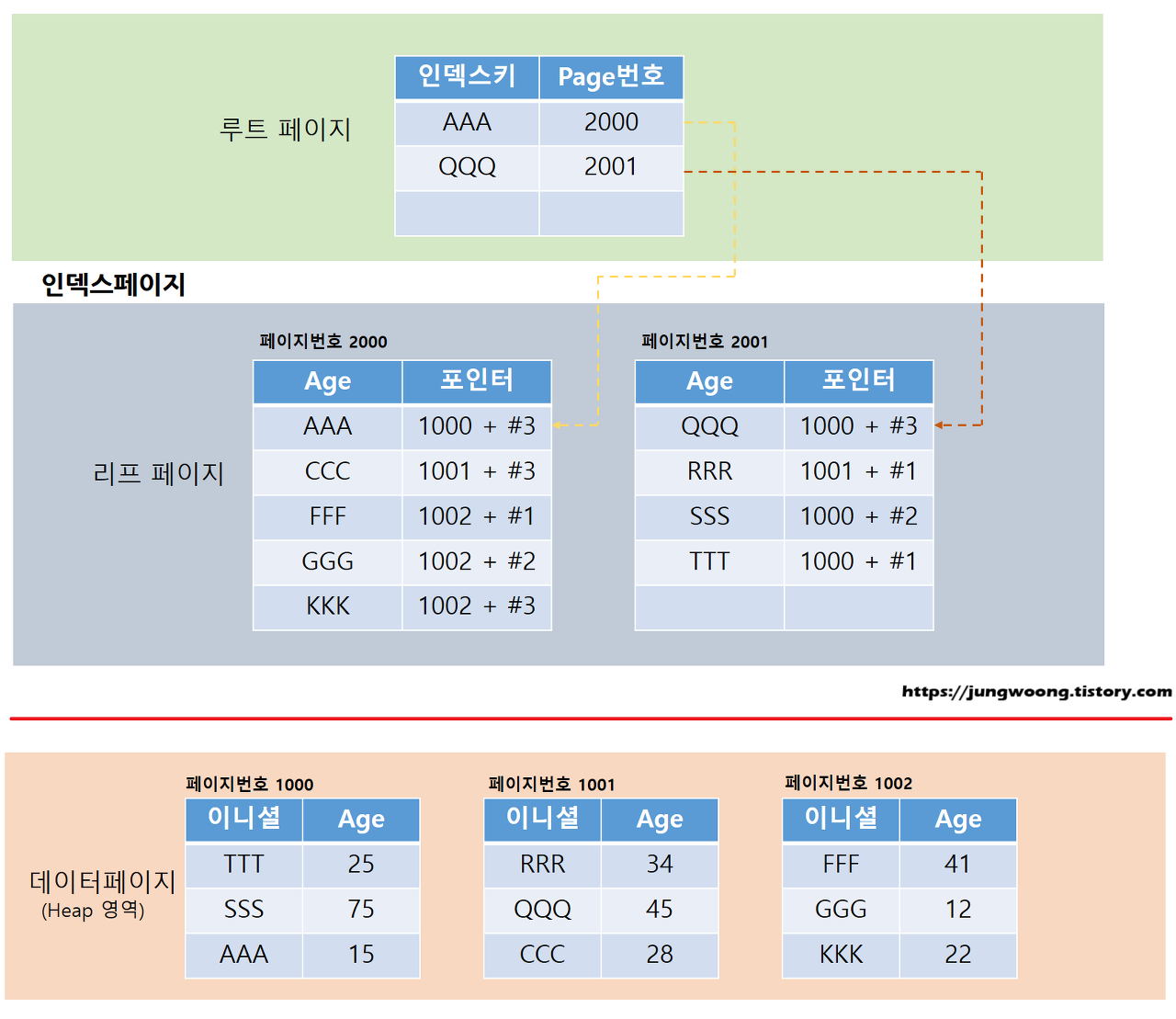
2. 비클러스터 인덱스 검색 시
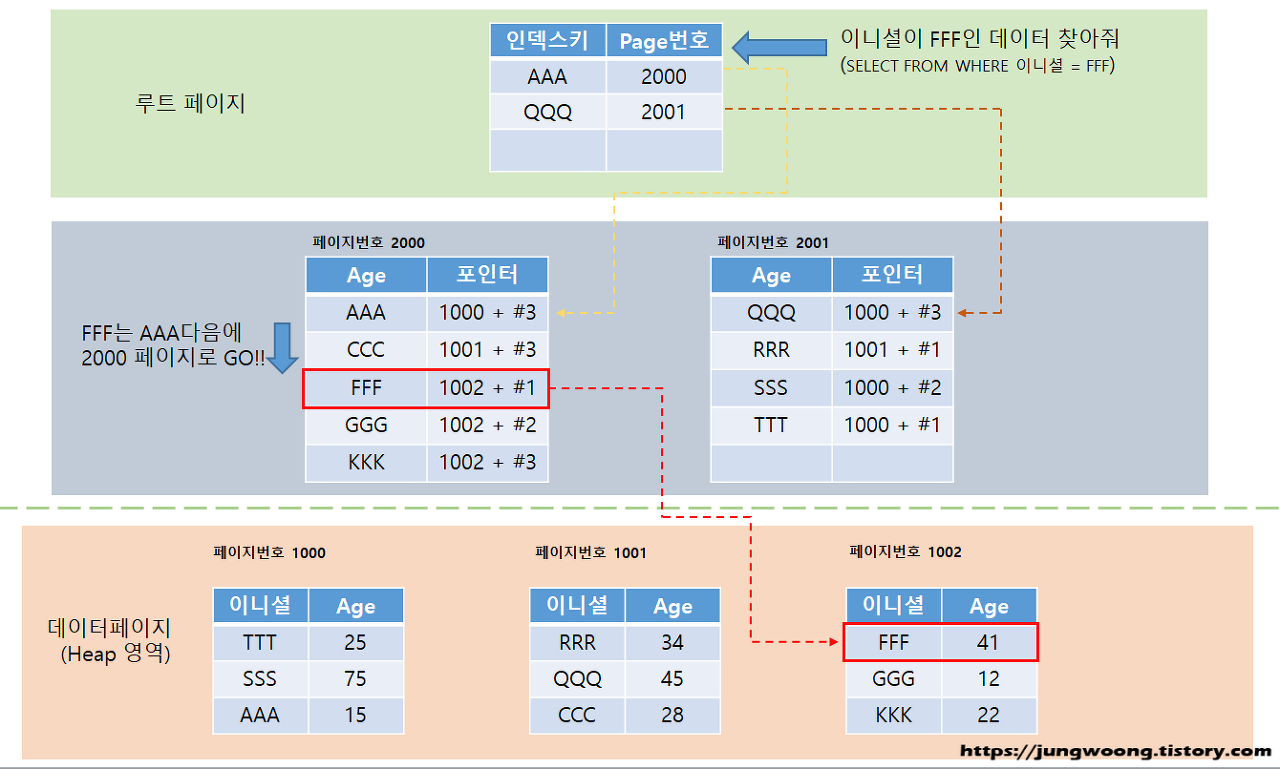
비클러스터에서 FFF인 데이터를 검색하는 로직을 실행하면 다음과 같은 과정을 거친다.
- 인덱스의 루트페이지를 접근해서 찾는 값이 어떤 리프 페이지에 있는지 확인한다.
- 리프 페이지로 이동 후에 페이지의 내부 행들을 검색해서 데이터의 포인터 정보에 접근합니다.
- 포인터 정보를 기반으로 데이터 페이지에 접근합니다.
검색 과정에서 총 3개의 페이지(루트 페이지 + 리프 페이지 + 데이터 페이지)를 참조하게 된다.
3. 비클러스터 인덱스 범위 검색 시
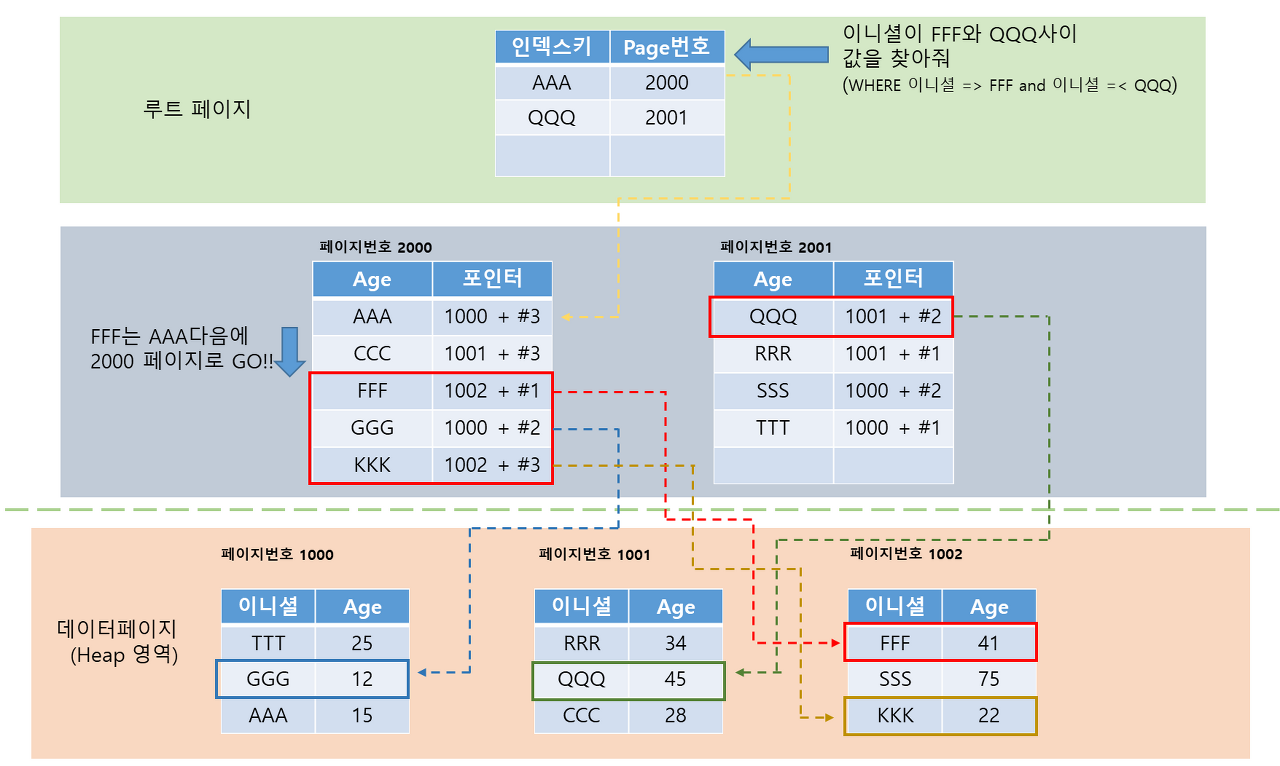
비클러스터에서 FFF에서 QQQ 사이의 범위의 데이터를 검색하는 로직을 실행해보자. 클러스터 인덱스의 경우는 데이터가 정렬되어 있기 때문에 FFF만 찾으면 다음 데이터들이 순차적으로 접근이 가능하지만, 비클러스터 인덱스의 경우에는 데이터가 정렬되어 있지 않기 때문에 검색하려는 범위 데이터 수 * 비클러스터 인덱스 검색 로직의 반복 작업이 필요하다. 이 때문에 범위 검색의 크기가 전체 테이블의 5% 이상이 된다면 인덱스를 사용하지 않고 Table scan 작업이 더 빠르기 때문에, DB 내부에서 자동으로 비클러스터 인덱스를 사용하지 않도록 실행 계획을 세운다. 위와 같이 동작하기 때문에 비클러스터 인덱스에 범위 검색을 사용할 때는 주의해서 사용해야 합니다.
4. 비클러스터 인덱스 삽입 시
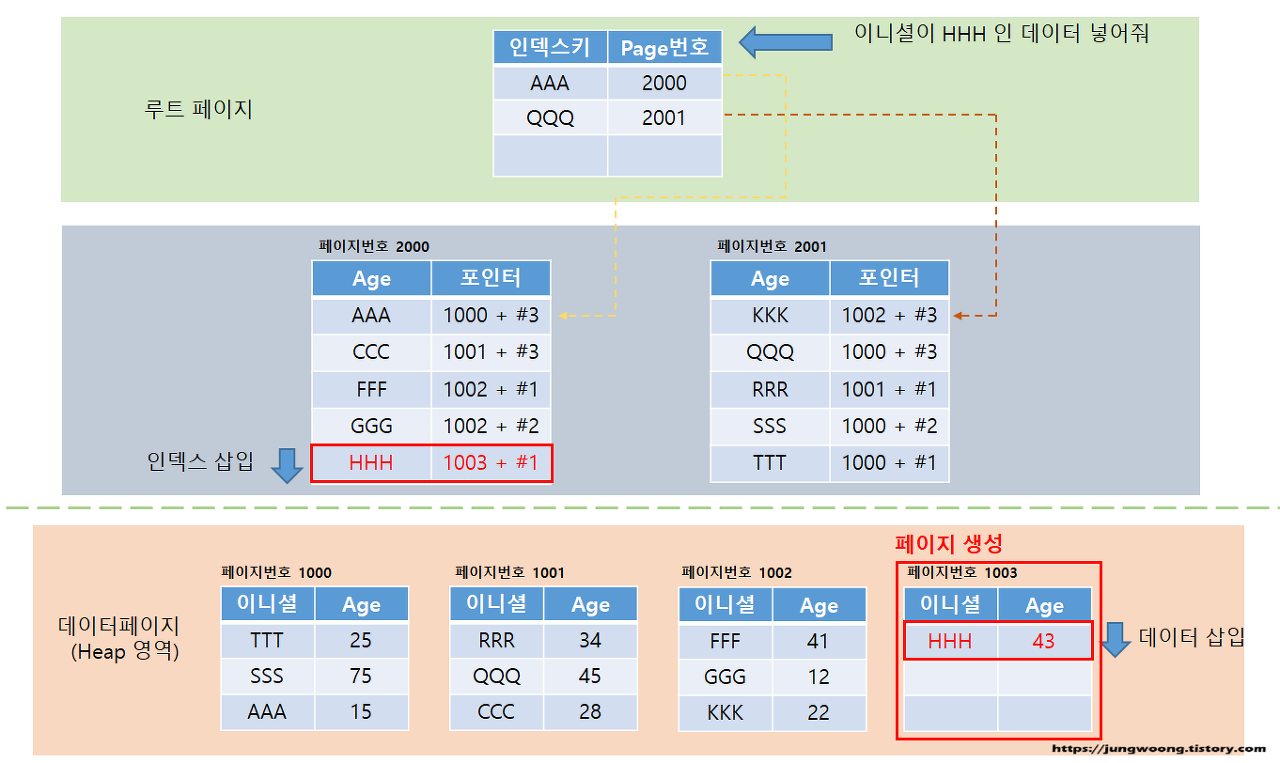
비클러스터 인덱스의 삽입은 인덱스의 리프 페이지에는 컬럼 순으로 삽입이 되고, 실제 데이터 페이지의 데이터는 삽입 순서대로 추가된다.
참고
MySQL의 기본 페이지 크기는 16KB이므로 훨씬 많은 행 데이터가 들어간다. 참고로 MySQL의 페이지 크기는 SHOW VARIABLES LIKE 'innodb_page_size'문으로 확인할 수 있다. 또한 필요 시 4KB, 8KB, 16KB, 32KB, 64KB로 변경할 수도 있다.
정리
클러스터 인덱스의 특징
- 인덱스를 생성할 때 데이터 페이지 전체가 다시 정렬된다. 이미 대용량 데이터가 입력된 상태에서 중간에 클러스터형 인덱스를 생성하면 시스템에 심각한 부하를 줄 수 있다.
- 리프 페이지가 곧 데이터 페이지이다. 인덱스 자체에 데이터가 포함되어 있다.
비클러스터 인덱스보다 검색 속도가 빠르고, 데이터 변경(삽입, 수정, 삭제) 속도는 느리다.
→ 클러스터형 인덱스에서는 루트 페이지와 리프 페이지로 총 2개의 페이지만 읽으면 되지만, 비클러스터형 인덱스에서는 인덱스 페이지의 루트 페이지, 리프 페이지, 데이터 페이지로 총 3개의 페이지를 읽어야 한다. 따라서 클러스터형 인덱스가 검색 속도가 더 빠르다.
→ 범위로 검색하면 클러스터형 인덱스가 훨씬 속도가 빠르다. 왜냐하면 클러스터형 인덱스는 리프 페이지가 미리 정렬되어 있고, 이 리프 페이지가 곧 데이터 페이지이므로 범위로 검색할 때 성능이 우수하다.
- 클러스터형 인덱스는 테이블에 하나만 생성할 수 있다. 따라서 어느 열에 클러스터형 인덱스를 생성하는 지에 따라 시스템의 성능이 달라진다.
비클러스터 인덱스의 특징
- 인덱스를 생성할 때 데이터 페이지는 그대로 둔 상태에서 별도의 페이지에 인덱스를 구성한다.
- 리프 페이지에는 데이터가 아니라, 데이터가 위치하는 주소 값(RID)가 들어있다.
데이터 변경(삽입, 수정, 삭제) 시, 클러스터형 인덱스보다 성능 부하가 적다.
→ 클러스터형 인덱스의 데이터 삽입 과정을 보면 페이지 분할 작업이 다소 많이 일어나서 성능이 저하된다. 비클러스터형 인덱스는 클러스터형 인덱스에 비해 분할이 덜 일어나기는 해도 여전히 페이지 분할이 발생한다.
- 비클러스터 인덱스는 한 테이블에 여러 개를 생성할 수 있다. 하지만 함부로 남용하면 오히려 시스템의 성능을 떨어트리는 결과를 초래할 수 있으므로 필요한 열(컬럼)에만 생성해야 한다.
