인덱스 뜻, 작동 과정, 장단점, 특징
in Development on Database
인덱스 뜻, 작동 과정, 장단점, 특징
인덱스란 ?
인덱스는 데이터베이스에서 검색의 속도를 높이는 데 사용되는 자료구조이다. 쉽게 얘기하면, 인덱스는 책의 뒷부분에 실리는 ‘찾아보기(색인)’와 같은 개념이다. 책의 내용 중에서 특정 단어를 찾고자 할 때 처음부터 마지막 페이지까지 전부 넘기기보다는, 찾아보기에 있는 페이지를 보면 훨씬 빠르다. 실무에서 사용하는 데이터는 많게는 수천만, 수억 건 이상에 달하므로 인덱스 없이 전체 데이터를 찾는다는 것은 MySQL 입장에서 굉장히 부담스러운(시간이 오래 걸리는) 일이다. 실제로 실무에서도 인덱스를 잘 활용하지 못해서 시스템의 성능이 전체적으로 느린 경우가 흔히 있다.
조금 더 구체적으로 예를 들어 설명을 하자면, 찾아보기(인덱스)가 없는 책의 경우 첫 페이지부터 일일이 넘겨가면서 확인해보는 수 밖에 없다. 운이 좋아 앞부분에서 원하는 단어를 찾았더라도 그 단어가 한 번만 나온다는 보장이 없으니 마지막 페이지까지 계속 넘겨봐야 한다. 반면에 찾아보기(인덱스)가 있는 책은 찾아보기에 주요 용어가 가나다순, 알파벳순으로 정렬되어 있고 용어 옆에 쪽수가 적혀 있어 해당 페이지를 펼치면 원하는 내용을 바로 찾을 수 있다.
인덱스 생성 전후에 따른 데이터 조회 방식
밑과 같은 테이블이 있다고 가정하자. 그리고 임의의 데이터 500개가 들어있다고 가정하자. 밑과 같이 테이블을 생성하면, 아무 인덱스 없는 테이블이 생성된다.
CREATE TABLE indexTBL (
first_name varchar(14),
last_name varchar(16),
hire_date date
);
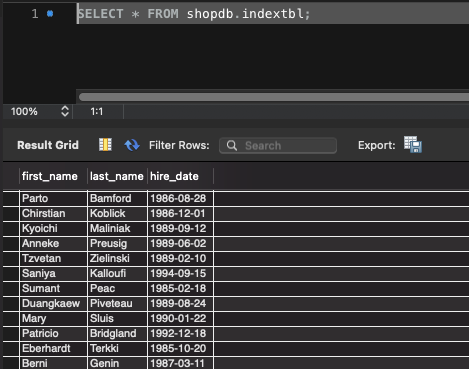
1. 인덱스가 없는 상태에서 쿼리 작동 확인하기
Workbench에서 Query가 어떤 형식으로 작동됐는 지 확인해보면, Full Table Scan(전체 테이블 스캔)의 방식을 활용했다.
SELECT * FROM indexTBL WHERE first_name = 'Mary';
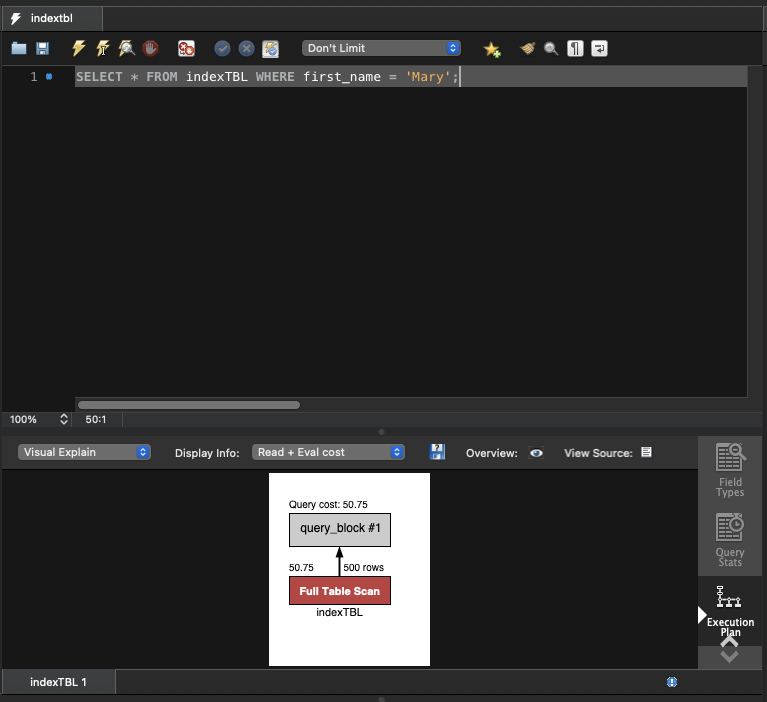
2. 인덱스 생성 후 쿼리 작동 확인하기
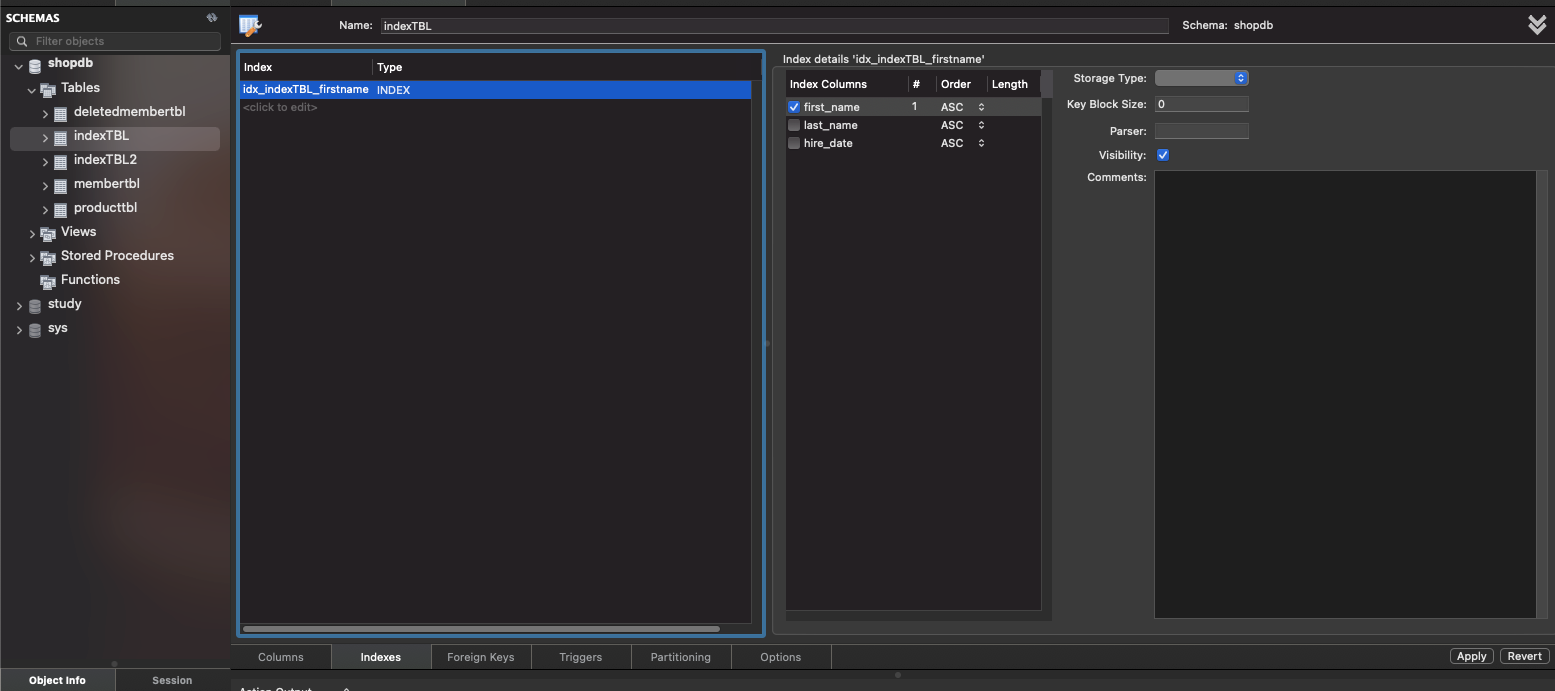
인덱스의 이름 idx_indexTBL_firstname은 indexTBL 테이블의 first_name 열에 생성된 인덱스가 된다. 사실 인덱스의 이름을 별로 중요하지 않지만, 지금처럼 이름만으로 어느 테이블의 어느 열에 설정된 인덱스인지 알 수 있도록 지정하는 것이 좋다.
CREATE INDEX idx_indexTBL_firstname ON indexTBL(first_name);
SELECT * FROM indexTBL WHERE first_name = 'Mary';
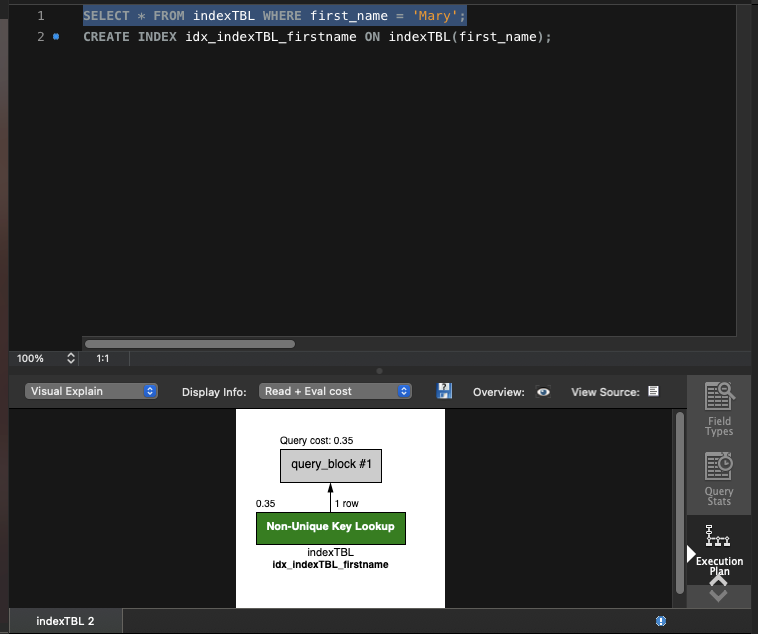
결론
인덱스를 생성하기 전의 쿼리는 책의 찾아보기(색인)가 없는 상태에서 특정 단어를 검색하는 것(책의 전체 페이지를 찾아보는 것)과 같고, 인덱스를 생성한 후의 쿼리는 책의 찾아보기(색인)가 있을 때 먼저 찾아보기에서 특정 단어를 찾아보고 그 페이지를 검색하는 것과 같다. 이처럼 인덱스를 생성한 후 조회하는 것은 데이터의 양에 따라서는 크게는 몇 십 배 이상 빠를 수도 있다.
실무에서는 필요한 열에 반드시 인덱스를 생성해야 한다. 한편 인덱스는 잘 사용하면 약이 되지만 잘못 사용하거나 함부로 남용하면 독이 될 수 있으므로 세심한 주의가 필요하다.
인덱스의 문제점
인덱스의 문제점을 책의 찾아보기에 빗대어 살펴보자. MySQL 관련 책의 경우 찾아보기에 MySQL이라는 단어가 등록되어 있을 것이다. 그런데 MySQL이라는 단어가 책의 거의 모든 페이지에 나오므로 찾아보기에 모두 표시한다면 쪽수가 수백 개일 것이다. 만약 찾아보기에 실린 단어가 모두 이런 식이라면 찾아보기의 부냘ㅇ이 엄청나게 많아져서 본문보다 더 두꺼워지는 난감한 상황이 될 수도 있다.
그럼에도 불구하고 일단 찾아보기를 통해 MySQL이라는 단어가 있는 모든 페이지를 펼쳐 본다고 하자. 찾아보기를 보고 해당 페이지를 펼치고, 찾아보기를 보고 해당 페이지를 펼치고, …찾아보기에 적혀 있는 모든 페이지를 이런 식으로 왔다 갔다 하며 반복할 것이다. 차라리 책을 첫 페이지부터 넘기면서 MySQL이라는 단어를 찾는 편이 훨씬 빠르고 효율적일 것이다. 찾아보기에 포함하지 말았어야 할 MySQL이라는 단어 때문에 쓸데없이 분량만 많아지고, 게다가 찾아보기를 사용하지 않을 때보다 단어를 찾는 시간이 더 걸린다.
실제 데이터베이스에서도 이와 비슷한 일이 일어난다. 필요 없는 인덱스를 만드는 바람에 데이터 베이스가 차지하는 공간만 늘어나고, 인덱스를 이용하여 데이터를 찾는 것이 전체 테이블을 찾아보는 것보다 훨씬 느린 경우가 있다.
참고) 이렇게 찾아보기를 사용하지 않고 책의 처음부터 끝까지 차례로 넘겨가며 찾는 것을 MySQL에서는 ‘전체 테이블 검색(FULL TABLE SCAN)이라고 한다.
인덱스의 장단점
장점
- 검색 속도가 매우 빨라진다. (항상 그런 것은 아니다.)
- 검색에 대한 쿼리의 부하가 줄어들어 결국 시스템 전체의 성능이 향상된다.
단점
- 인덱스를 저장할 공간이 필요하다. 대략 데이터베이스 크기의 10% 정도 추가 공간이 필요하다.
- 처음 인덱스를 생성하는 데 많은 시간이 소요된다.
- 데이터의 변경(삽입, 수정, 삭제) 작업이 자주 일어날 경우 오히려 성능이 나빠질 수 있다.
인덱스의 특징
- 인덱스는 테이블의 열(컬럼) 단위로 생성하는데, 하나의 열에 생성할 수도 있고 여러 열에 생성할 수도 있다.
- 테이블을 생성할 때 특정 열을 기본키(PRIMARY KEY)로 설정하거나, UNIQUE 제약 조건을 설정하면 그 열에 자동으로 인덱스가 생성된다.
- 기본키(PRIMARY KEY)가 테이블에 존재하면, 기본키가 무조건 그 테이블의 클러스터형 인덱스이다. 만약 기본키가 없다면 NOT NULL UNIQUE라는 조건이 붙어있는 열이 클러스터형 인덱스이다.
인덱스의 종류
MySQL에서 사용하는 인덱스에는 클러스터형 인덱스(clustered index)와 비클러스터형 인덱스(non-clustered index, 보조 인덱스)가 있다. 두 인덱스를 책에 비유하면 클러스터형 인덱스는 ‘영어 사전’과 같고 비클러스터 인덱스는 ‘찾아보기가 있는 책’과 같다.
클러스터형 인덱스는 영어 사전처럼 책의 내용 자체가 순서대로 정렬되어 있어 인덱스가 책의 내용과 같다. 그리고 비클러스터 인덱스는 찾아보기(색인)가 별도로 있고, 찾아보기(색인)에서 먼저 단어를 찾은 후 그 옆에 표시된 페이지로 이동하여 원하는 내용을 찾는 것과 마찬가지다.
1. 클러스터형 인덱스(clustered index)
- 테이블당 하나만 생성할 수 있다.
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동으로 정렬한다.
2. 비클러스터형 인데스(non-clustered index)
- 테이블당 여러 개를 생성할 수 있다.
자동으로 생성되는 인덱스
테이블을 생성할 때 특정 열을 기본키(PRIMARY KEY)로 설정하거나, UNIQUE 제약 조건을 설정하면 그 열에 자동으로 인덱스가 생성된다.
특징 1. 기본키(PRIMARY KEY)나 UNIQUE 제약 조건을 갖고 있는 열은 자동으로 인덱스가 생성된다.
CREATE TABLE userTBL
( userID char(8) NOT NULL PRIMARY KEY,
userName varchar(10) NOT NULL,
birthYear int NOT NULL,
address varchar(10) NOT NULL UNIQUE
);
SHOW INDEX FROM userTBL;

- Non_unique : 0이면 고유 인덱스를, 1이면 비고유 인덱스를 의미한다.
- Key_name : Index_name과 같은 의미로 인덱스 이름을 나타낸다.
- Seq_in_index : 해당 열에 여러 개의 인덱스가 설정되었을 때 순서를 나타낸다.
- Cardinality : 중복되지 않은 데이터의 개수가 들어있다.
- Null : NULL 값 허용 여부를 나타내는 데, 비어 있으면 NULL을 허용하지 않는다는 것을 의미한다.
- Index_type : 인덱스가 어떤 형태로 구성되었는 지를 나타낸다. MySQL은 기본적으로 B-Tree 구조이다.
특징 2. 기본키(PRIMARY KEY)를 가진 컬럼이 있으면, 그 컬럼이 자동으로 ‘클러스터형 인덱스’로 생성된다.
CREATE TABLE userTBL
( a INT PRIMARY KEY,
b INT UNIQUE,
c INT UNIQUE
);
SHOW INDEX FROM userTBL;

INSERT INTO userTBL VALUES (500, 2, 2);
INSERT INTO userTBL VALUES (200, 3, 3);
INSERT INTO userTBL VALUES (300, 1, 1);
SELECT * FROM userTBL;
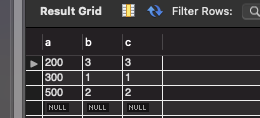
a 컬럼을 기준으로 정렬되어서 조회된 것으로 보았을 때, a 컬럼이 클러스터형 인덱스임을 알 수 있다.
특징 3. 기본키(PRIMARY KEY)를 가진 컬럼이 없을 경우, NOT NULL UNIQUE 제약조건이 있는 컬럼이 클러스터형 인덱스로 선정된다.
CREATE TABLE userTBL
( a INT NOT NULL UNIQUE,
b INT UNIQUE,
c INT UNIQUE
);
SHOW INDEX FROM userTBL;

INSERT INTO userTBL VALUES (500, 2, 2);
INSERT INTO userTBL VALUES (200, 3, 3);
INSERT INTO userTBL VALUES (300, 1, 1);
SELECT * FROM userTBL;
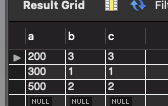
특징 4. 기본키(PRIMARY KEY)를 가진 컬럼이 없을 경우, NULL을 허용하는 UNIQUE 제약 조건만 있을 때에는 클러스터형 인덱스가 생성되지 않는다. 단지 비클러스터 인덱스만 생성된다.
CREATE TABLE userTBL
( a INT UNIQUE,
b INT UNIQUE,
c INT UNIQUE
);
SHOW INDEX FROM userTBL;

INSERT INTO userTBL VALUES (500, 2, 2);
INSERT INTO userTBL VALUES (200, 1, 1);
INSERT INTO userTBL VALUES (300, 3, 3);
SELECT * FROM userTBL;
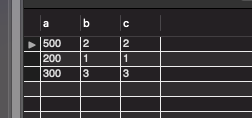
만약 클러스터형 인덱스가 적용이 됐더라면, 클러스터형 인덱스가 적용된 열을 기준으로 정렬이 됐어야 한다. 하지만 위의 조회 결과를 봤을 때 아무 것도 정렬이 되어있지 않다.
특징 5. 기본키(PRIMARY KEY)를 가진 컬럼과 NOT NULL UNIQUE 제약조건을 가진 컬럼이 둘 다 있을 경우, 기본키를 가진 컬럼이 클러스터형 인덱스로 선정된다.
CREATE TABLE userTBL
( a INT NOT NULL UNIQUE,
b INT PRIMARY KEY,
c INT UNIQUE
);
SHOW INDEX FROM userTBL;

INSERT INTO userTBL VALUES (500, 2, 2);
INSERT INTO userTBL VALUES (200, 3, 3);
INSERT INTO userTBL VALUES (300, 1, 1);
SELECT * FROM userTBL;
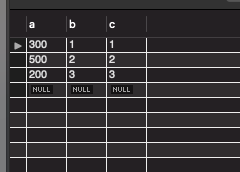
인덱스 생성 기준
인덱스는 자라 사용할 경우 쿼리의 성능이 급격히 향상되지만, 그렇지 않으면 쿼리의 성능과 함께 전반적인 성능도 떨어뜨릴 수 있어 유의해야 한다. 인덱스를 반드시 만들어야 한다는 절대 기준이 있는 것은 아니다. 테이블의 데이터 구성이 어떠한지, 테이블에서 어떤 작업을 많이 하는지 등을 고려하여 인덱스를 생성할 것인지 말 것인지를 판단해야 한다. 인덱스 생성의 판단 기준은 다음과 같다.
인덱스는 열 단위에 생성한다.
인덱스는 하나의 열에만 생성할 수 있는 것이 아니라 2개 이상의 열을 조합해서 생성할 수도 있다.
인덱스는 WHERE 절에 사용되는 열에 만든다.
회원 테이블에 아이디(userID), 이름(userName), 출생 연도(birthYear), 주소(addr) 컬럼이 있다고 가정하자. 그런데 WHERE 절에 사용되는 컬럼은 대부분 아이디만 사용한다.
SELECT userName, birthYear, addr FROM userTBL WHERE userID = 'KHD';
따라서 이름, 출생 연도, 주소에는 인덱스를 생성하지 않고, 아이디(userID) 컬럼에만 인덱스를 생성해야 한다.
WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있다.
위의 쿼리에서 아이디(userID) 열에 인덱스를 생성하여 효율이 좋아진다고 하더라도 위의 SELECT 문을 아주 가끔 사용하고 INSERT(삽입) 작업이 많이 일어난다면 어떨까? 게다가 아이디 열에 생성된 인덱스가 클러스터형 인덱스라면? 오히려 인덱스 때문에 데이터 삽입 시 성능이 더 나빠질 것이다. WHERE 절에 사용되는 열이라고 해서 인덱스를 생성하는 것이 무조건 좋은 것만은 아니다. 자주 사용되는 열에 인덱스를 생성해야 효율을 높일 수 있다.
데이터 중복도가 높은 열에는 인덱스를 만들어도 효과가 없다.
employess 테이블에 gender라는 열이 있고, 이 열에는 입력할 수 있는 데이터가 남성을 의미하는 M과 여성을 의미하느나 F뿐이라고 가정해보자. 이처럼 거의 같은 데이터가 있는 열은 비클러스터형 인덱스를 만들어도 MySQL이 사용하지 않거나, 사용하더라도 큰 성능 향상 효과를 보지 못할 가능성이 많다. 오히려 인덱스를 관리하는 데 비용이 들어가 인덱스가 없는 편이 나을지도 몰ㄴ다. 따라서 데이터 중복도가 높은 열에 인덱스를 만들 때는 신중하게 판단해야 한다.
외래키를 설정한 열에는 자동으로 외래키 인덱스가 생성된다.
외래키 제약 조건을 설정한 열에는 자동으로 인덱스가 생성된다. 그리고 쿼리문에서 외래키 인덱스가 필요한 경우 MySQL이 알아서 외래키 인덱스를 사용한다.
조인(JOIN)에 자주 사용되는 열에는 인덱스를 생성하는 것이 좋다.
조인과 관련된 열에는 인덱스를 생성하는 것이 성능 향상에 도움이 된다.
데이터 변경(삽입, 수정, 삭제) 작업이 얼마나 자주 일어나는 지 고려한다.
인덱스는 검색할 때만 시스템의 성능을 향상하고, 데이터 변경(삽입, 수정, 삭제) 작업을 할 때는 성능을 떨어트린다. 인덱스를 많이 만들어도 성능에 문제가 되지 않는 테이블은 삽입 작업이 거의 일어나지 않는 테이블이다.
하지만 대부분의 온라인 트랜잭션 처리 데이터베이스에는 데이터 변경 작업이 자주 일어난다. 따라서 필요 없는 열에 인덱스를 생성하면 성능에 나쁜 영향을 미칠 수 밖에 없다. 인덱스를 만들어 데이터 검색 시 성능을 높일 것인지, 인덱스를 만들지 않아 데이터 변경 시의 영향을 최소화할 것인지 잘 결정해야 한다.
클러스터형 인덱스는 테이블당 하나만 생성할 수 있다.
클러스터형 인덱스를 생성하는 열에 범위(BETWEEN, >, < 등) 조건이나 집계 함수가 설정되어 있으면 좋다. 앞에서 설명했듯이 클러스터형 인덱스는 데이터 페이지를 읽는 수륻 최소화하여 성능을 향상하므로, 검색 조건으로 가장 많이 사용되는 열에 생성하는 것이 바람직하다. 또한 ORDER BY 절에 자주 나오는 열에 클러스터형 인덱스를 설정해도 좋다. 클러스터형 인덱스의 데이터 페이지(리프 페이지)가 이미 정렬되어 있기 때문이다.
테이블에 클러스터형 인덱스가 아예 없는 것이 좋은 경우도 있다.
클러스터형 인덱스가 꼭 있어야 한다고 오해하기도 하는데, 클러스터형 인덱스가 없는 편이 더 나은 경우도 종종 있다. 밑과 같은 회원 테이블이 있다고 가정하자.
CREATE TABLE userTBL
( userID char(8) NOT NULL PRIMARY KEY, // 클러스터형 인덱스
userName varchar(10) NOT NULL,
birthYear int NOT NULL,
...
)
이런 상태에서 대용량 데이터가 무작위로 아이디(userID)의 순서와 관계없이 삽입된다고 가정해보자. 회원 테이블은 클러스터형 인덱스로 구성되어 있으므로, 데이터가 삽입됨과 동시에 정렬이 계속 수행되고 페이지 분할이 끊임없이 일어나 시스템의 성능에 문제가 발생할 것이다. 이럴 때는 차라리 클러스터형 인덱스가 없는 편이 낫다. 즉 아이디 열을 기본키로 설정하지 않고, UNIQUE로 설정하는 것이 좋다.
CREATE TABLE userTBL
( userID char(8) **NULL UNIQUE**,
userName varchar(10) NOT NULL,
birthYear int NOT NULL,
...
)
주의할 점은 UNIQUE에 NOT NULL을 함께 설정하면, 클러스터형 인덱스가 생성되므로 NULL로 설정해야 한다는 것이다. UNIQUE로 설정한 아이디 열에 반드시 값을 입력해야 한다면 회원 가입 화면에서 아이디를 필수로 입력하도록 프로그래밍 하는 것이 좋다.
사용하지 않는 인덱스는 제거한다.
운영 중인 응용 프로그램의 쿼리를 분석하여 WHERE 조건에 사용되지 않는 열에 인덱스가 설정되어 있다면 제거한다. 인덱스를 제거하면 추가 공간을 확보할 수 있을뿐더러 데이터를 삽입할 때 발생하는 부하도 줄일 수 있다.
